Precision Medicine
The age of affordable massively parallel sequencing has exponentially increased the availability of genome and transcriptome profiling. Extracting biologically and clinically meaningful results from these massive, complex data remains challenging. The analysis and interpretation ofsequence data remains the major bottleneck in many settings. This workshop aims to address this bottleneck by conferring core competencies and specific skills for processing the sequencing data deluge.
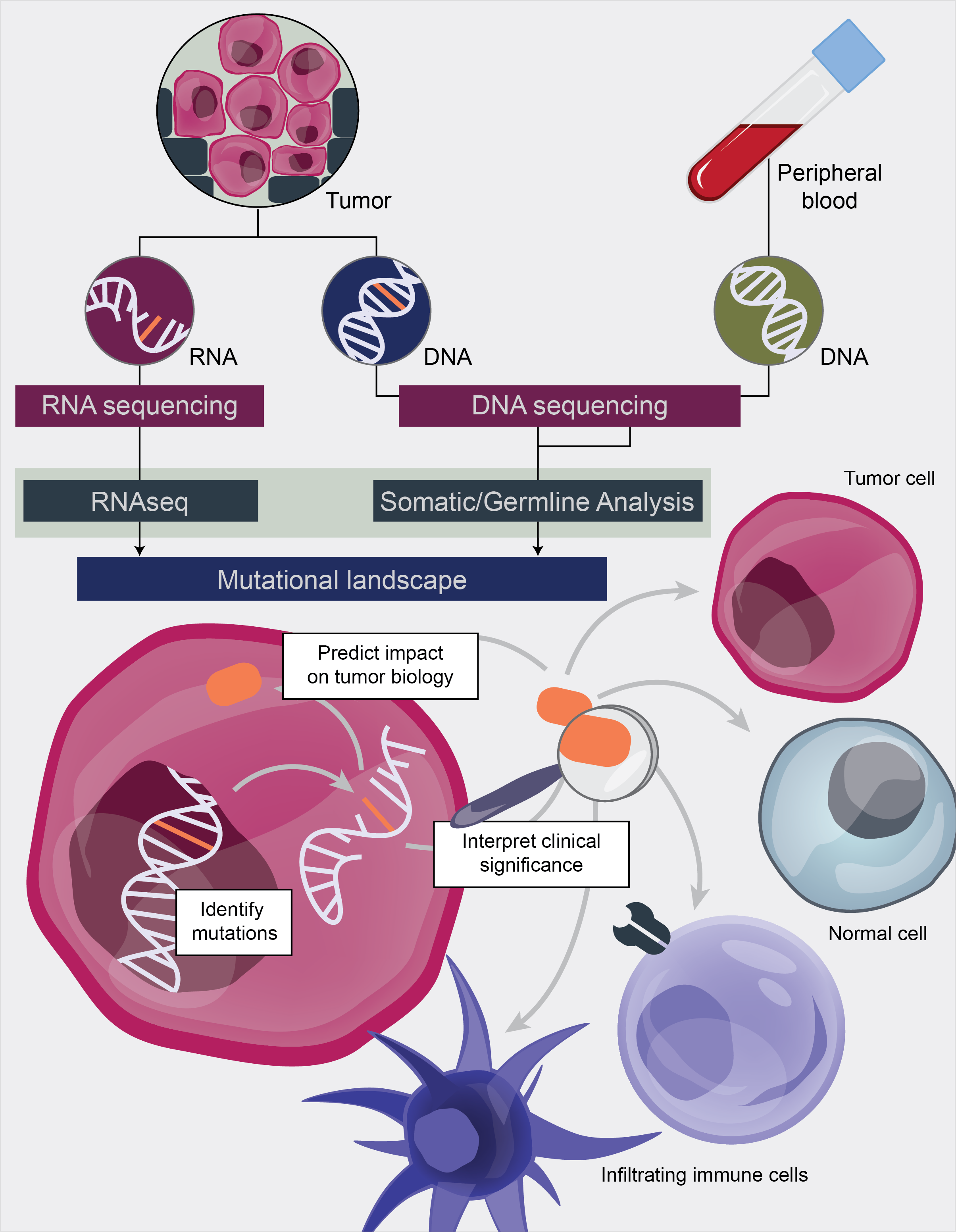
Analysis of high throughput genome and transcriptome data is a major component of many research projects ranging from large-scale precision medicine efforts to focused investigations in model systems. This analysis involves the identification of specific genome or transcriptome features that predispose individuals to disease, predict response to therapies, influence diagnosis/prognosis, or provide mechanistic insights into disease models. During this course (IBDR01), students will perform an example end-to-end bioinformatics analysis of genome (WGS and Exome) and transcriptome (RNA-seq) data.
Students will start with raw sequence data for a hypothetical patient case, learn to install and use the tools needed to analyze this data on the cloud, and visualize and interpret results. After completing the course, students should be in a position to (1) understand raw sequence data formats, (2) perform bioinformatics analyses on the cloud, (3) run complete analysis pipelines for alignment, variant calling, annotation, and RNA-seq (transcriptome analysis approaches will be a major component of the workshop), (4) visualize and interpret whole genome, exome and RNA-seq results, (5) leverage the identification of passenger variants for immunotherapy or minimal residual disease applications, and (6) begin to place these results in a clinical context by use of variant knowledgebases. The data, tools, and analysis will be most directly relevant to human genomics and bioinformatics research. However, many of the skills and concepts covered will be applicable to other human diseases and model organisms. Furthermore, many analysis concepts covered during the workshop will be broadly applicable to other “big data” research problems.
This website provides a current version of all course materials (including copies of presentations, practical exercises, data files, and example scripts prepared by the instructing team). This website is meant to accompany an in-person workshop delivered by the researchers who created it. However, anyone is free to use this site to learn these concepts on their own. Please navigate to Course to begin.
We are constantly improving the course material, if you notice a problem or have a suggestion for improvement please let us know by making a github issue at: https://github.com/griffithlab/pmbio.org/issues